IT용어
RAG (Retrieval-Augmented Generation)
미니임
2026. 2. 27. 21:30
1. 개요 (Overview)
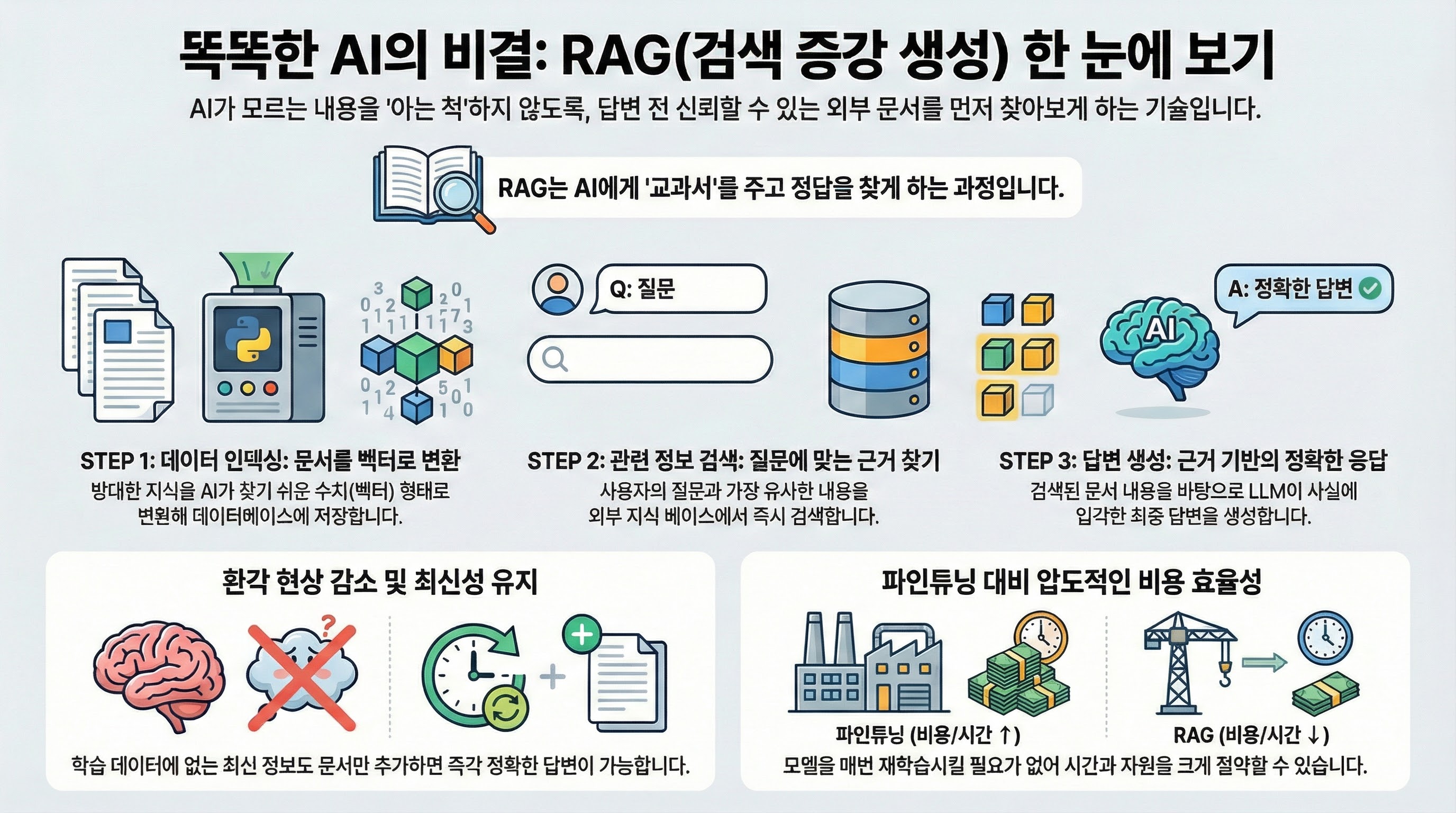
**RAG(검색 증강 생성)**는 거대 언어 모델(LLM)의 출력을 최적화하여, 응답을 생성하기 전에 학습 데이터 소스 외부의 신뢰할 수 있는 지식 베이스를 참조하도록 하는 기술입니다.
LLM은 학습된 시점 이후의 정보를 알지 못하거나(지식의 컷오프), 사실이 아닌 정보를 그럴듯하게 말하는 환각(Hallucination) 현상이 발생할 수 있습니다. RAG는 모델이 질문에 답하기 전 관련 문서를 먼저 "찾아보고(Retrieval)", 그 내용을 바탕으로 답변을 "생성(Generation)"하게 함으로써 이 문제를 해결합니다.
2. RAG의 작동 프로세스
RAG의 일반적인 워크플로우는 다음의 단계를 거칩니다.
- 데이터 수집 및 인덱싱 (Indexing): 방대한 문서 데이터를 텍스트 조각(Chunk)으로 나누고, 이를 벡터(Vector) 형태로 변환하여 벡터 데이터베이스에 저장합니다.
- 사용자 질문 (Querying): 사용자가 질문을 던지면, 질문 역시 벡터로 변환됩니다.
- 검색 (Retrieval): 질문 벡터와 가장 유사한 정보를 가진 데이터 조각을 벡터 DB에서 찾아냅니다.
- 증강 (Augmentation): 검색된 정보와 원래의 질문을 결합하여 LLM에 전달할 프롬프트를 구성합니다.
- 생성 (Generation): LLM은 제공된 맥락(Context)을 바탕으로 최종 답변을 생성합니다.
3. 기술 스택 (Technology Stack)
RAG 시스템을 구축하기 위해 필요한 핵심 기술 요소들입니다.
구분주요 기술 및 도구설명
| LLM (생성 모델) | GPT-4o, Claude 3.5, Llama 3, Mistral | 최종 답변을 생성하는 두뇌 역할 |
| Embedding Model | OpenAI Text-Embedding-3, Hugging Face 모델 | 텍스트를 기계가 이해하는 수치(벡터)로 변환 |
| Vector Database | Pinecone, Milvus, Weaviate, Chroma, FAISS | 대규모 벡터 데이터를 저장하고 유사도 검색 수행 |
| Orchestration Framework | LangChain, LlamaIndex | 데이터 로드, 임베딩, 검색, 생성 과정을 연결하는 프레임워크 |
| ETL Pipeline | Unstructured.io, PyPDF2 | PDF, HTML, Docx 등 다양한 문서에서 텍스트 추출 |
4. RAG의 주요 특징
4.1. 환각 현상 감소 (Hallucination Mitigation)
모델의 기억력에만 의존하는 것이 아니라, 제공된 근거 문서에 기반하여 답변하므로 오답을 말할 확률이 현격히 낮아집니다.
4.2. 최신성 유지 (Up-to-date Information)
모델을 다시 학습(Fine-tuning)시키지 않고도, 데이터베이스의 문서만 교체하거나 추가하면 즉시 최신 정보를 반영할 수 있습니다.
4.3. 설명 가능성 및 투명성 (Explainability)
답변의 근거가 된 출처(Source)를 사용자에게 함께 제시할 수 있어 결과에 대한 신뢰도를 높일 수 있습니다.
4.4. 비용 효율성 (Cost-Efficiency)
매번 새로운 데이터를 학습시키는 파인튜닝 방식에 비해 컴퓨팅 자원과 비용이 훨씬 적게 듭니다.
5. RAG vs Fine-tuning 비교
비교 항목RAG (검색 증강 생성)Fine-tuning (미세 조정)
| 주요 목적 | 새로운 지식/정보의 주입 | 특정 말투, 형식, 도메인 지식 최적화 |
| 최신성 반영 | 실시간 업데이트 가능 (매우 쉬움) | 재학습 필요 (느림) |
| 환각 현상 | 낮음 (근거 기반) | 발생 가능성 있음 |
| 구현 난이도 | 중 (데이터 파이프라인 구축) | 상 (데이터셋 구축 및 모델 학습) |
6. 주요 활용 사례 (Use Cases)
- 기업용 내부 지식 검색 (Enterprise Search): 사내 규정, 프로젝트 문서, 기술 사양서 등을 기반으로 직원들의 질문에 답변하는 챗봇.
- 고객 지원 솔루션 (Customer Support): 최신 제품 매뉴얼과 FAQ를 실시간으로 참조하여 정확한 상담 서비스를 제공.
- 법률 및 의료 문서 분석: 방대한 판례법이나 의학 논문 중에서 질문과 관련된 내용을 찾아 요약 및 분석.
- 개인화된 비서 서비스: 사용자의 이메일, 일정, 메모 등 개인 데이터를 안전하게 참조하여 맞춤형 정보 제공.
- 코드 생성 보조: 사내의 고유한 라이브러리나 코딩 컨벤션을 참조하여 프로그래밍 가이드 제공.
7. 향후 과제 및 고도화 전략 (Advanced RAG)
단순한 RAG를 넘어 성능을 극대화하기 위한 연구가 진행 중입니다.
- Hybrid Search: 키워드 기반 검색(BM25)과 벡터 기반 검색(Semantic)을 결합.
- Re-ranking: 검색된 결과 중 가장 관련성 높은 결과의 순위를 다시 매기는 과정.
- Query Transformation: 사용자의 모호한 질문을 검색에 최적화된 질문으로 재구성.
- Agentic RAG: 에이전트가 스스로 판단하여 어떤 도구를 쓸지, 검색이 더 필요한지 결정하는 구조.
반응형