젠슨 황의 선언: "1조 달러 규모의 AI 인프라 시대와 물리적 AI의 도래"
이번 GTC 2026 기조연설에서 젠슨 황 CEO는 2027년까지 전 세계 AI 인프라 수요가 1조 달러(약 1,300조 원) 규모에 달할 것이라고 전망했습니다. 특히 과거의 AI가 단순히 정보를 학습(Training)하는 단계였다면, 이제는 실시간으로 사고하고 행동하는 **추론(Inference)과 에이전틱 AI(Agentic AI)**가 주류가 되었음을 강조했습니다. 이를 뒷받침하기 위해 엔비디아는 컴퓨팅, 메모리, 네트워킹을 집대성한 차세대 하드웨어 플랫폼을 대거 투입했습니다.
1. 차세대 '루빈(Rubin)' 아키텍처 및 하드웨어 세부 스펙 분석
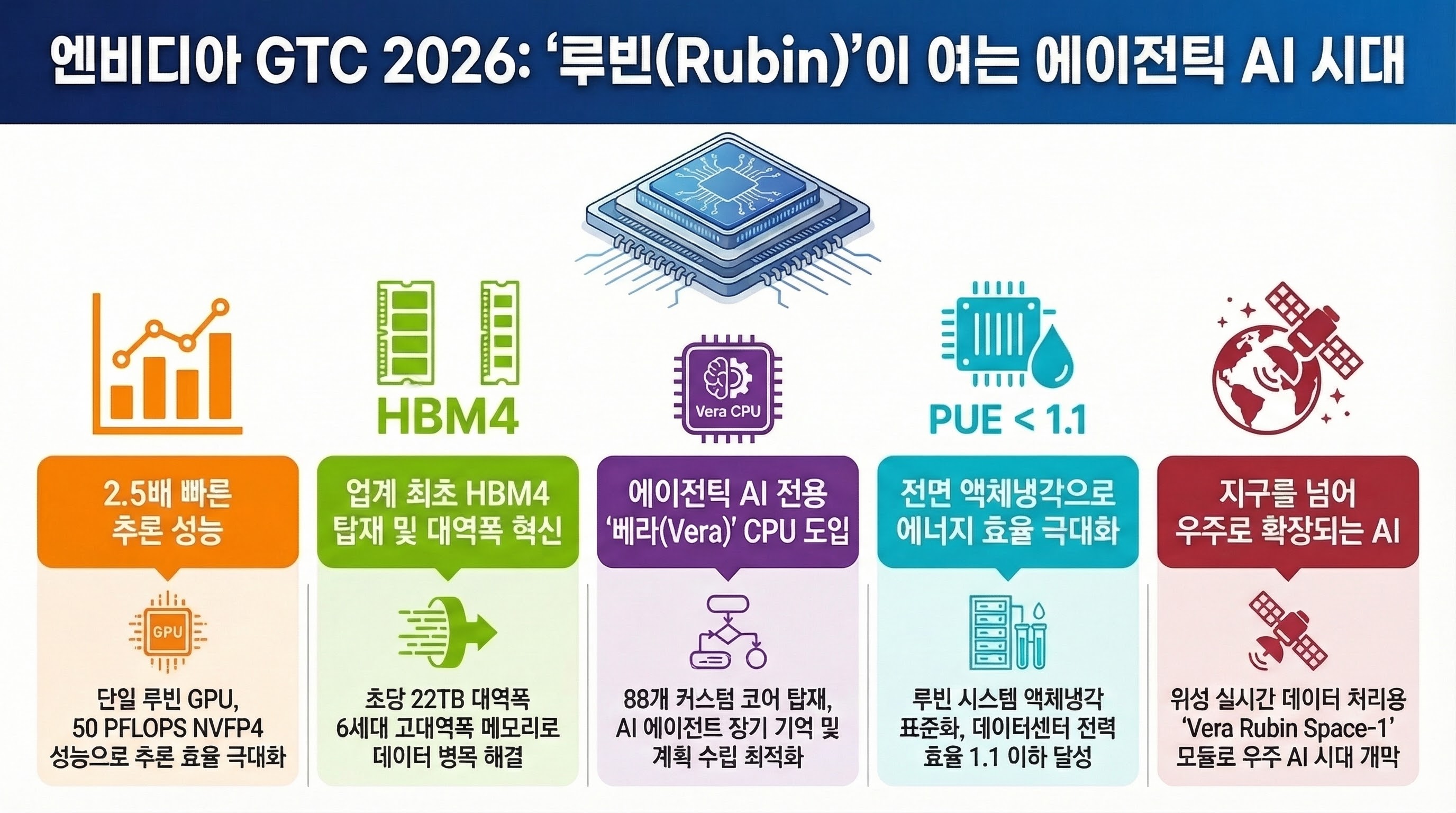
엔비디아 루빈 아키텍처는 이전 세대인 블랙웰(Blackwell)을 뛰어넘는 압도적인 수치를 기록했습니다. 특히 **HBM4(6세대 고대역폭 메모리)**의 최초 도입과 NVFP4라는 새로운 정밀도 도입이 핵심입니다.
핵심 하드웨어 사양
- 컴퓨팅 성능: 단일 루빈 GPU는 **50 PFLOPS(페타플롭스)**의 NVFP4 추론 성능을 제공합니다. 이는 블랙웰 대비 약 2.5~3배 향상된 수치입니다.
- 메모리 혁신: 업계 최초로 12단(12-Hi) 및 16단(16-Hi) HBM4를 탑재했습니다. 대역폭은 초당 22TB/s에 달하며, 단일 칩당 메모리 용량은 288GB로 확장되었습니다.
- 베라(Vera) CPU: 기존 그레이스(Grace) CPU를 대체하는 베라 CPU는 88개의 커스텀 Olympus ARM 코어를 탑재했습니다. 초당 1.2TB/s의 LPDDR5X 메모리 대역폭을 지원하며, 에이전트의 장기 기억(Memory)과 계획 수립(Planning) 처리에 최적화되었습니다.
- NVLink 6 및 네트워크: 6세대 NVLink는 GPU 간 대역폭을 3.6TB/s로 끌어올렸으며, 새로운 ConnectX-9 SuperNIC는 초당 1.6Tb/s의 초고속 이더넷 통신을 지원합니다.
2. 블랙웰(Blackwell) vs 루빈(Rubin) 성능 비교
엔비디아는 인프라 효율성을 극대화하기 위해 '베라 루빈(Vera Rubin) NVL72' 시스템을 전면에 내세웠습니다. 아래 표는 이전 세대 최고 사양인 블랙웰 울트라와 루빈의 주요 지표를 비교한 것입니다.
세대별 성능 비교표
| 구분 | 블랙웰 울트라 (GB300 NVL72) | 베라 루빈 (VR NVL72) | 향상 폭 |
| 추론 성능 (FP4) | 1.44 ExaFLOPS | 3.6 ExaFLOPS | 약 2.5배 |
| GPU 메모리 타입 | HBM3e | HBM4 | 세대 교체 |
| 메모리 대역폭 | 8 TB/s | 22 TB/s | 2.75배 |
| NVLink 대역폭 | 1.8 TB/s | 3.6 TB/s | 2배 |
| 네트워킹 (NIC) | 800 Gb/s (CX-8) | 1.6 Tb/s (CX-9) | 2배 |
| 냉각 방식 | 하이브리드 / 액체냉각 | 전면 액체냉각 (Liquid-Cooled) | 효율 최적화 |
3. 주요 기술 트렌드 및 산업 확장
전면 액체냉각 시스템의 표준화
루빈 플랫폼의 TDP(열설계전력)가 칩당 1,000W~1,200W를 상회함에 따라, 엔비디아는 모든 루빈 시스템에 액체냉각(Liquid Cooling) 도입을 공식화했습니다. 이는 데이터센터의 에너지 소비 효율(PUE)을 1.1 이하로 낮추는 핵심 기술로 자리 잡았습니다.
우주 및 물리적 AI로의 확장
이번 GTC에서는 지구를 넘어선 'Vera Rubin Space-1' 모듈이 공개되었습니다. 궤도 데이터센터를 위해 설계된 이 모듈은 H100 대비 25배 높은 AI 연산력을 제공하며, 위성에서 수집된 방대한 데이터를 지상 전송 없이 실시간으로 처리하는 기능을 갖췄습니다. 또한, 현대·BYD 등 주요 완성차 업체와 협력하여 자연어로 대화하고 판단을 설명하는 '알파마요(Alpamayo)' 자율주행 모델을 선보였습니다.
4. 향후 로드맵 및 시장 전망
엔비디아는 루빈의 후속 아키텍처로 **'파인만(Feynman)'**을 언급하며, 1년 단위의 하드웨어 갱신 주기를 유지할 것임을 분명히 했습니다. 루빈 기반의 제품군은 2026년 하반기부터 주요 파트너사인 Supermicro, QCT, Dell 등을 통해 본격적으로 공급될 예정입니다.
업계 전문가들은 루빈 플랫폼이 거대언어모델(LLM)의 토큰 생성 비용을 블랙웰 대비 10분의 1 수준으로 낮춤으로써, 기업용 AI 에이전트 시장이 폭발적으로 성장할 것으로 보고 있습니다.
출처: NVIDIA Official Newsroom, StorageReview, Tom's Hardware
원문 보기: * NVIDIA GTC 2026 Keynote Recap: Structured Data Is the Ground Truth