
티스토리 뷰
1. 개요 (Overview)
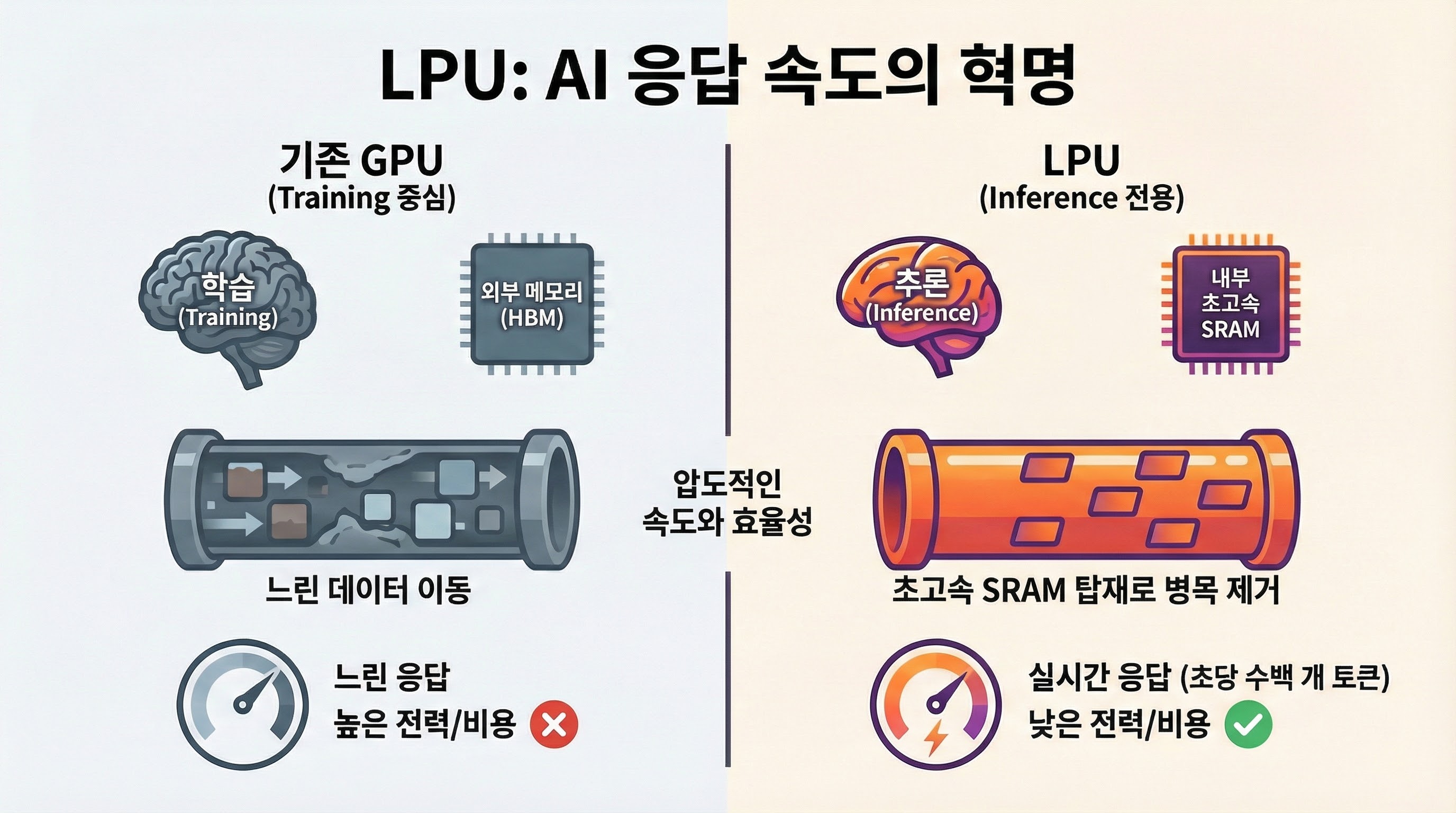
**LPU(Language Processing Unit)**는 생성형 AI, 특히 거대언어모델(LLM)의 추론(Inference) 단계를 가속화하기 위해 설계된 새로운 유형의 프로세서입니다. 미국의 AI 칩 스타트업인 **Groq(그록)**이 처음으로 제안한 개념으로, 기존의 GPU가 그래픽 처리나 AI 학습(Training)에 범용적으로 사용되는 것과 달리, LPU는 언어 모델의 순차적 토큰 생성 특성에 최적화되어 있습니다.
핵심은 "지연 시간(Latency)"의 극단적인 단축과 "초당 토큰 처리량(Throughput)"의 극대화에 있습니다.
2. 기술 스택 및 아키텍처 (Tech Stack & Architecture)
LPU의 성능은 하드웨어와 소프트웨어의 긴밀한 통합에서 비롯됩니다.
1) 텐서 스트리밍 아키텍처 (Tensor Streaming Architecture, TSA)
LPU는 전통적인 폰 노이만 구조의 병목 현상을 해결하기 위해 TSA를 채택합니다. 이는 데이터가 프로세서를 통과하며 실시간으로 처리되는 방식으로, 데이터 이동에 소요되는 시간을 최소화합니다.
2) 메모리 기술: SRAM (Static Random Access Memory)
- SRAM 탑재: GPU가 대용량 고대역폭 메모리(HBM)를 사용하는 것과 달리, LPU는 칩 내부에 초고속 SRAM을 직접 탑재합니다.
- 장점: HBM보다 훨씬 빠르고 전력 소모가 적습니다. 다만, 용량이 작기 때문에 대규모 모델을 돌리기 위해서는 여러 개의 LPU를 네트워크로 연결하는 클러스터링이 필수적입니다.
3) 결정론적 하드웨어 (Deterministic Hardware)
- LPU는 하드웨어 수준에서 작업의 실행 시간을 100% 예측할 수 있도록 설계되었습니다. 스케줄러가 하드웨어가 아닌 컴파일러(Software)에 의해 제어되므로 지터(Jitter)가 거의 없습니다.
4) GroqWare 소프트웨어 스택
- Groq Compiler: PyTorch나 TensorFlow로 작성된 모델을 LPU에 최적화된 기계어로 변환합니다. 수동 최적화 없이도 하드웨어의 최대 성능을 끌어냅니다.
3. 핵심 특징 (Key Characteristics)
특징설명
| 극도로 낮은 지연 시간 | LLM 응답을 실시간 대화 수준(초당 수백 토큰)으로 출력합니다. |
| 높은 에너지 효율 | HBM을 거치지 않고 내부 SRAM에서 처리하므로 추론 시 전력 효율이 GPU보다 우수합니다. |
| 순차적 처리 최적화 | LLM의 특성인 '다음 단어 예측'의 순차적 연산에 특화되어 병목 현상이 없습니다. |
| 확장성 | 수만 개의 LPU를 연결하여 단일 가상 칩처럼 작동하게 하는 네트워킹 기술을 지원합니다. |
| 단순한 제어 | 복잡한 제어 로직을 컴파일러가 담당하여 하드웨어 구조가 단순하고 효율적입니다. |
4. LPU vs GPU 비교
구분GPU (NVIDIA H100 등)LPU (GroqChip)
| 주 목적 | 범용 그래픽 처리, AI 학습 및 추론 | LLM 추론 가속화 전용 |
| 메모리 유형 | HBM (High Bandwidth Memory) | SRAM (Static RAM) |
| 데이터 처리 | 대규모 병렬 처리 (SIMT) | 스트리밍 기반 결정론적 처리 |
| 장점 | 학습 효율성, 광범위한 생태계 | 추론 속도, 낮은 지연 시간 |
| 단점 | 추론 시 지연 시간 발생 가능성 | 상대적으로 적은 메모리 용량 |
5. 주요 활용 사례 (Use Cases)
1) 실시간 AI 에이전트 및 챗봇
고객 서비스나 개인 비서 서비스에서 사용자의 질문에 즉각적으로 반응해야 하는 경우 LPU가 필수적입니다. 인간의 읽기 속도보다 빠른 토큰 생성이 가능합니다.
2) 실시간 동시 통역
음성을 텍스트로 변환(STT)하고 번역한 뒤 다시 음성으로 출력(TTS)하는 과정에서 발생하는 지연 시간을 최소화하여 끊김 없는 동시 통역을 구현합니다.
3) 대규모 코드 생성 및 분석
수천 줄의 코드를 순식간에 생성하거나 대규모 코드베이스를 실시간으로 분석하여 개발 생산성을 극대화합니다.
4) 실시간 복합 추론 (Multi-step Reasoning)
복잡한 문제를 해결하기 위해 AI가 내부적으로 여러 단계의 사고를 거쳐야 할 때, 각 단계의 추론 속도가 빨라야 전체 응답 시간을 단축할 수 있습니다.
6. 결론 및 향후 전망
LPU는 "AI의 일상화"를 위해 가장 중요한 요소인 추론 비용 절감과 사용자 경험(속도) 개선을 동시에 해결할 수 있는 기술입니다. 비록 학습 분야에서는 여전히 GPU가 우위에 있지만, 서비스 상용화 단계인 추론 시장에서는 LPU와 같은 특화 프로세서(ASIC)의 영향력이 급격히 커질 것으로 전망됩니다.
'IT용어' 카테고리의 다른 글
| sLLM (Small Large Language Model) (0) | 2026.03.10 |
|---|---|
| RAG (Retrieval-Augmented Generation) (0) | 2026.03.10 |
| 서버리스(Serverless) (0) | 2026.02.27 |
| DX (Digital Transformation) (0) | 2026.02.27 |
| SaaS (Software as a Service) (0) | 2026.02.27 |
- Total
- Today
- Yesterday
- HBM
- 스마트안경
- CSS
- HTML
- 웹기초
- 협력
- java
- 엣지컴퓨팅
- on-device ai
- prompt engineering
- CSR
- Rag
- LLM
- Javascript
- AI
- react
- It용어
- SSR
- MSA
- Nextjs
- 카카오
- sLLM
- 구글
- 멀티모달
- TypeScript
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 |